主题
GLM-5.1:当国产大模型学会刷榜,却还没学会干活
一位不想用但忍不住用了的开发者,谈GLM-5.1的真实体验。
2026年3月底,智谱AI发布了GLM-5.1。朋友圈和自媒体瞬间刷屏——"国产之光""超越Claude 94.6%""性价比之王"……各种标题党层出不穷,仿佛中国AI的天终于亮了。
说实话,我一直不想用。
不是偏见,是经验。从GLM-3到GLM-4,再到GLM-5,每一次发布会都是"史诗级进步",每一次实际使用都是"史诗级失望"。我本以为自己已经免疫了。
但人嘛,总忍不住想看看这次是不是真的不一样。
先说句公道话
写这篇测评之前,我得先亮明一个立场:我是认可GLM的,至少在国产大模型里,它是我的"首选"。
作为一名重度依赖AI编程的开发者,我几乎试过了市面上所有主流大模型的编程能力。如果让我给编程能力打分(满分100,Claude和GPT在我心中是90分以上的存在),GLM在我这里能拿到60分——刚好及格。
这个分数什么概念?它是我心目中仅次于Claude和GPT的编程模型。 没错,在我个人使用体验中,GLM的编程能力甚至比Google Gemini还要好用一点。这在国产模型里已经是天花板级别的存在了。
所以当我批评GLM-5.1的时候,不是因为它"太差",而是因为它"本可以更好"。
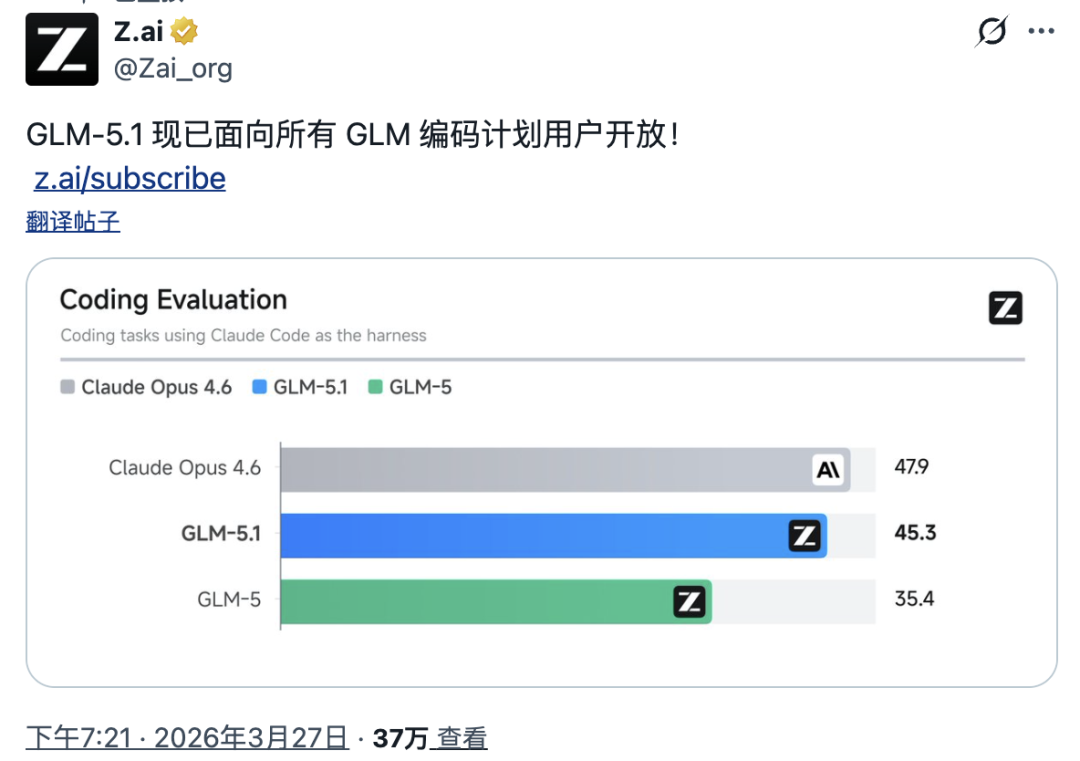
公平起见,GLM-5.1也有它的亮点。智谱官方宣称它在编程评测中拿到了45.3分,比上一代GLM-5的35.4分提升了28%。如果只看这个数字,它和Claude Opus 4.6的47.9分只差2.6分,达到了94.6%的水平。
另外,价格确实便宜。GLM Coding Plan最低月费3美元,正式价10美元起步。相比之下,Claude Max的费用确实高出一大截。
如果你只看PPT和评测分数,这确实是个"颠覆性"的产品。
但实际体验呢?
我从发布第一天就开始认真测试了GLM-5.1,主要场景是代码生成、Agent任务和长上下文处理。以下是我的真实感受。
1. 200K上下文?别人去年就1M了
GLM-5.1发布会上有一个被反复提及的"亮点"——支持200K的上下文窗口和128K的最大输出长度。
听起来很厉害对吧?
但让我们把时间线拉出来看看:Claude在2024年就支持了200K上下文,到2025年已经全面升级到1M。GPT系列同样在2025年就实现了百万级上下文窗口。
也就是说,GLM-5.1在2026年拿出来的,是竞争对手一两年前的水平。
这就像2026年发布一款新手机,宣传语是"支持5G网络",而友商已经普及6G了。你不是在创新,你是在追赶,而且追得还不太紧。
更关键的是,GLM-5.1的200K上下文还只是"纸面参数"。实际测试中,当你输入超过80K的上下文时,模型就开始出现明显的注意力衰减——前面的指令被忽略,中间的逻辑被跳过,只对最后几万token的内容有响应。所谓的200K,更像是"能塞进去,但不一定能消化"。
相比之下,Claude和GPT在接近上下文上限时依然能保持相对稳定的理解能力,这才是真正的差距。
2. 响应慢得让人怀疑人生
GLM-5.1的推理速度只有44.3 tokens/秒,在同类产品中几乎是最慢的。写一段中等复杂度的代码,等它生成完的时间足够我去泡杯咖啡。而Claude Sonnet同样的任务,输出速度快了不止一倍。
速度慢不是致命问题,但当它慢的同时还频繁卡死、中断任务,这就很难接受了。
更离谱的是,在长上下文场景下,速度还会进一步下降。当你给它喂入大量代码让它分析时,响应延迟可以从几秒飙升到几十秒,甚至直接超时。这对于需要频繁交互的开发工作流来说,体验极差。
3. Agent模式形同虚设
GLM-5.1大肆宣传"Agentic Engineering"能力——自动规划、验证、修复代码,甚至生成压力测试脚本。听起来很美好对吧?
实际用起来,Agent模式下的问题层出不穷:
- 工具调用不稳定:Web Search功能会突然介入并干扰当前任务,导致代码生成中断。你让它写一个函数,它写着写着突然去搜了个网页,然后忘了自己在写什么。
- 多步任务翻车:让它完成一个需要5-6个步骤的任务,前三步勉强能跟上,到第四步开始"放飞自我",要么跳过关键步骤,要么执行错误的操作。
- 长上下文中的幻觉:在Agent模式下处理较长对话时,模型会开始"发明"不存在的API、编造不存在的文件路径,甚至声称已经完成了实际上根本没做的操作。
作为一个每天深度使用AI Agent的开发者,我可以负责任地说:GLM-5.1的Agent能力,目前还处于"能Demo不能交付"的阶段。如果你拿它去做真正的生产任务,光调试它的错误输出所花的时间,可能比你自己手写还长。
4. 基准测试≠实际能力
这是最让我反感的一点。
智谱给出的评测数据都是自报的,目前没有任何独立第三方的验证结果。而所有收钱的自媒体都在用这些数据大做文章,"超越Claude 94.6%"被反复引用,仿佛这就是事实。
但任何一个真正深度使用过这些模型的人都知道,差距远不止5.4%。
评测分数和实际体验之间的鸿沟,主要来自几个方面:
第一,评测场景过于理想化。 标准化的编程评测题和真实的工程开发完全是两回事。就像驾考满分不代表你能开好山路,评测高分不等于模型能处理复杂的、模糊的、需要多轮迭代的生产级任务。
第二,自报分数缺乏可信度。 智谱没有公开评测的完整数据集和详细分数 breakdown。你告诉我总分45.3,但各子项表现如何?在哪些类型的任务上强、哪些弱?一概不知。
第三,对标模型的选择有技巧。 "达到Claude Opus 4.6的94.6%"这个表述本身就有误导性。为什么不和Claude Sonnet比?不和GPT-4o比?选择对标对象本身就是一种叙事策略。
这就像一个学生说自己数学考了94.6分,但试卷是自己出的,答案也是自己判的,而且只和班上第二名的同学比。你信吗?
5. 创意写作和长文本依然拉胯
除了编程,我测试了几个创意写作和长文本理解的任务。结果和GLM-5基本一个水平:
- 创意内容干瘪无味:让它写文案、写故事,输出就像是把一堆关键词拼接在一起,缺乏灵气、缺乏节奏感、缺乏真正"人味"的表达。
- 长对话中经常遗漏指令:聊了十几轮之后,它会开始"选择性遗忘"你之前给出的规则和约束。
- 逻辑连贯性差:长文本生成时经常前后矛盾,第三段说的话和第一段完全对不上。
6. 生态体验差距巨大
很多人只关注模型本身的能力,却忽略了一个更重要的维度:生态体验。
用Claude或GPT,你得到的是什么?
- 成熟稳定的API服务,99.9%的可用性
- 完善的文档和开发者工具
- 丰富的第三方集成和插件生态
- 持续迭代的产品体验,每一次更新都经过充分测试
用GLM-5.1,你得到的是什么?
- 经常性的限流和服务波动
- 文档不完善,很多功能需要自己摸索
- 第三方生态几乎为零
- 每次更新都像是"赶工交付",Bug比Feature多
这不是模型能力的差距,这是工程成熟度的差距。而后者,往往比前者更难追。
顺带给国产大模型排个名
既然聊到这儿了,不如把我个人的编程能力评测排名也摆出来,供大家参考。
这是基于我大量实际使用后得出的主观排名,不涉及任何评测分数,纯粹是干活时的体感:
第一梯队(真正能用的):
- Claude — 编程领域的王者,代码质量、逻辑推理、长上下文理解全面领先
- GPT — 综合能力最强,编程能力紧随Claude,生态最完善
第二梯队(勉强能用的):
- GLM — 国产最强,60分及格线,简单到中等复杂度的任务可以胜任
- Gemini — Google出品,编程能力其实还不错,但在我的使用场景中略逊于GLM
第三梯队(勉强能看但不太敢用):
- Kimi — 月之暗面出品,偶尔能给出还行的方案,但稳定性差,经常需要反复调教
- MiniMax — 速度快但错误率高,之前我专门写过一篇批判文章,"快但不可靠"是它的致命伤
第四梯队(基本不及格):
- Qwen(通义千问) — 阿里的模型,编程能力在国产里算中等,但离"能用"还有距离
- 豆包(字节跳动) — 对话还行,编程真的不行,生成的代码经常跑不起来
- DeepSeek — 吹得最凶,实际编程体验最让人失望。开源做得好不代表产品好用
排不上号的:
- 小米、混元、百川、零一万物……这些模型在编程领域和上面这些完全不是一个量级,差距大到你甚至不需要认真对比。
所以你看,GLM虽然被我批评,但它好歹是国产里"唯一一个能过及格线的"。我批评它,是因为我对它期望最高;而那些连及格线都够不着的,我连批评的欲望都没有了。
算力是根本问题
有科技博主深度测试后发现,GLM-5.1的实际体验差,很大一部分原因是算力不足。模型本身的能力可能还不错,但受限于算力分配和速率上限,普通用户的体验被严重拖累。甚至有博主怀疑,GLM-5.1可能是"量化+蒸馏"的产物——为了降低推理成本,牺牲了模型的表现。
从GLM-4.7到GLM-5再到GLM-5.1,智谱每次发布新模型都会出现限流和服务波动。这说明什么?说明算力基础设施根本没跟上模型迭代的速度。
你造了一辆法拉利,但只修了一条乡间小路,这有什么意义?
国产大模型的真实差距
我不想泼冷水,但事实就是事实。
GPT和Claude之所以强大,不仅仅是因为模型本身,更因为它们背后有:
- 成熟的推理基础设施:分布式计算、负载均衡、弹性扩容,样样都是世界级水平
- 完善的多模态能力:图像、视频、音频,全面覆盖且持续领先
- 稳定的API服务:企业级可靠性,这是生产环境的基本要求
- 数百万用户的真实反馈:每一行代码、每一次交互都在帮助模型变得更好
国产大模型目前在做什么?刷评测分数、搞低价营销、请自媒体吹捧。
这些当然也需要,但如果你连最基本的"能用、好用、稳定"都做不到,刷再高的分数也只是自嗨。
写在最后
我不是不希望国产大模型变好。恰恰相反,我比任何人都希望有一天能用上真正好用的国产AI。毕竟,谁不想用更便宜、更懂中文的模型呢?
但"希望"不能代替"事实"。理性的批评,才是对国产大模型最大的帮助。
GLM-5.1相比上一代确实有进步,这是值得肯定的。但距离GPT、Claude这种真正能投入生产使用的模型,还有很远的距离。这个差距不是刷几个评测分数、发几篇通稿就能弥合的。
少刷榜,多干活。少吹牛,多打磨。少找自媒体带货,多听听真实用户的反馈。
这才是国产大模型该走的路。
作为一名长期使用各类AI模型的开发者,我的建议是:如果你需要一个真正靠谱的编程助手,Claude Sonnet/Opus依然是首选。如果你预算有限想试试国产模型,GLM-5.1可以玩玩,但别对它抱太高期望。
省下的钱,最后可能都要花在修复它生成的bug上。
毕竟,时间才是最贵的成本。